| GISdevelopment.net ---> AARS ---> ACRS 1995 ---> Spatial Information Processing |
Comparison of the Certainties
in a GIS
D.Arnarsaikhan,
M.Ganzorig
Informatics & RS Centre, Mongolian Academy of Sciences
av.Enkhtaivan-54B, Ulaanbaatar-51, Mongolia
Abstract Informatics & RS Centre, Mongolian Academy of Sciences
av.Enkhtaivan-54B, Ulaanbaatar-51, Mongolia
At present there are many techniques for land cover mapping using . RS data. The results of various parametric and non-parametric , classifications with different certainties (qualities) are put to . a GIS and used in decision making. The most commonly used . algorithms are the parametric and non-parametric (eg, k-nearest . neighbor maximum likelihood classifiers against which other . classification algorithms are compared. Various authors have used the Dempster-Shafer theory of evidence for the land cover , discrimination and argued that the result is better than the result of the standard maximum likelihood classification. The aim of the study is to compare these methods. For the comparison, two different natural regions have been selected. 1
1. Introduction
The linkage between RS and GIS can be made automatically by the use of some pattern recognition techniques and manually by a visual interpretation. Over the years, researchers have developed various techniques to improve the classification results. The results of the existing classification techniques containing various certainties can be put into a GIS or directly used in some decision making. The processing steps of RS data to be used in a decision making process is shown in Figure 1. When the result of an image classification is used to update a layer of a GIS or in a decision making process the requirements proposed by Mulder et al. (1990) and Arnarsaikhan et al. (1992) should be met. Traditionally, the parametric maximum likelihood classification incorporating a priori probabilities or ancillary data is considered as one of the most efficient methods for the spectral classification. However, it has many limitations; for instance, in practice it is rare that the reflectance values have a multivariate normal distribution (Ince 1987, Mulder et al. 1990) .A number of authors (eg, Srinivasan and Richards 1990, Bronsveld et al. 1992) used the theory of evidence in the classification process and judged that the result is better than the result of the standard maximum likelihood classification. However, assumptions made in the Dempster theory are weaker than those made in the maximum likelihood classification, because it uses some assumptions (eg, AnB) used in fuzzy logic schemes. These techniques have been tested in two different natural regions. The results showed that by the use of the same technique, different results can be expected according to the context of the area.
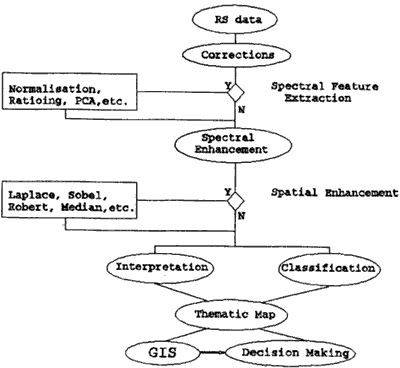
Figure 1 Processing Steps of RS Data to Update a GIS
2. The Test Sites and Materials
2.1. The first target area selected was in the central part of
Mongolia, near Ulaanbaatar city and has various natural diversities. In this area, the boundaries between the object classes are hardly distiguishable, and it is not easy to choose the satisfactory training samples. In this area soil, vegetation and water classes were selected.
2.1.1. For this area, a Landsat TM image of 1990 has been selected. In the maximum likelihood classification bands 2, 3,4 and in the classification which uses the theory of evidence bands 3 and 4 were used, respectively. A landuse map was produced using a knowledge of a specialist who worked for a long time in the study area.
2.2. The second test area was selected in the south eastern part of the country. The area is related to the steppe zone and during the summer time the land in this region is mainly covered by grass. For our study, we selected a part where vegetation, soil and solonchak are clearly separable from each other. In this area soil, vegetation and solonchak classes were selected.
2.2.1. For the image classification, 3 bands (green, red and NIR} of MSK-4 data converted to a digital format were used. The data were resampled to a spatial resolution of 30 meters. The band selection and a landuse map production in the area have the same procedures as mentioned above (see section 2.1.1}.
In both cases, the training samples (total of 180 to 240 pixels for each class} were selected avoiding multimodel and asymmetric distributions.
3. The Methods and Results
3.1. The idea of the Dempster-Shafer theory is to break down large datasets into components for each of which the probability judgements are made. Description and application of the theory in RS can be found in Srinivasan et al. (1990) and Brnsveld et al. (1992) .In the theory, the beliefs are combined according to the Dempster's rule of combination, which is expressed as follows:
Under this rule, the mass committed to a subset A under Bel is
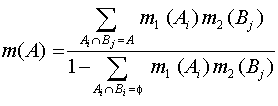
In the theory belief is non-additive, Bel(A)+Bel(Ø A) # 1
where Bel (ØA) is belief against A.
Ignorance = 1-{Bel(A)+Bel(ØA)}
Plausibility(A) = 1-Bel(ØA)
In the Dempster's rule the belief functions must be independent and must refer to the same frame of discernment(8). As discussed in Srinivasan et al. (1990) a direct application of the theory is complicated because all labels within the frame of discernment have to be compared with each other. To make a practical use some restrictions should be made. In our study, we used the following restrictions made in Bronsveld et al. (1992).
Bel (Q) is assumed to be always 0.9.
Only the belief against a particular label is expressed, consequently only the plausibility of each label can be calculated. By expressing only belief against a label the need to compare all possible combinations of the labels is not necessary. The final label for a pixel is classified after all the evidence' is used according to the following rules: The label is picked then the label with the least belief against that label is chosen, if two or more labels have the same amount of minimum belief against them, one of them is chosen. According to the rules, both test sides were classified and the overall classification accuracies were 88.14% for the first area and 84.16% for the second area, respectively.
3.2. To perform maximum likelihood classification for each image, the training samples were selected through thorough analysis. The pixels representing the interested classes were selected from different places of the images and then merged. The overall classification accuracy for the first area was 82.02% and for the second area it was 86.19%.
4. Conclusions
In this study, we compared one of the widely used classification techniques with the latest developed technique. As seen from the analysis, the traditional technique gives more accurate result in case of homogeneous area. This means, using the same technique different results can be expected according to the context of the area.
References
- Amarsaikhan, D., Gorte, B., 1992, Knowledge-based Approach to Update Landuse Layer of an Operational GIS, Proceedings of ACRS, Ulaanbaatar, Mongolia.
- Amarsaikhan, D., Ganzorig, M., 1994, Modification of the Prior Probabilities in the Maximum Likelihood Classification, Proceedings of ACRS, Bangalore, India.
- Bronsveld, K., and Kostwinder, H., 1992, Improving a Landuse Map using GIS and RS, International Symp. RS and Space '92, Hat Yai, Thailand.
- Ince, F., 1987, Maximum Likelihood Classification, Optimal or Problematic? A Comparison with the Nearest Neighbour Classification, International Journal of RS, Vol.8, No.12, 1829- 1839.
- Mulder, N.J., and Middelkoop, H., 1990, Parametric Versus Non- Parametric Maximum Likelihood Classification, Proceedings of ISPRS Symposium, Wuhan, China.
- Srinivasan, A., and Richards, J.A., 1990, Knowledge Based Techniques for Multi-source Classification, International Journal of Remote Sensing.