| GISdevelopment.net ---> AARS ---> ACRS 1999 ---> Hyper Spectral Image Processing |
Different Approaches in
Nature Extraction for Hyperspectral Image Classification
D.A. marsaikhan, M.
Gangorig
Institute of Informatics and R.S, Mongolian Academy of Science,
Av. Enkhataivan-54B, Ulaanbaatar-51, Mongolia
Abstract Institute of Informatics and R.S, Mongolian Academy of Science,
Av. Enkhataivan-54B, Ulaanbaatar-51, Mongolia
This paper describes different approaches in feature extraction for a hyper spectral image classification. For the actual feature extraction, principal components transformations, band correlation method, average intensity of the visible/infrared ranges and spectral knowledge are used. The output of each of the feature extraction method is used for a classification process. The results are analyzed and compared.
Introduction
Extraction of a reliable feature and improvement in a classification accuracy have been one of the main tasks of many researchers dealing with a digital image processing. Over the years, many techniques have been developed and tested for processing and analysis of convectional multispectral data with fewer dimensionality. For such data, feature extraction can be easily done via either less correlated bands or transforming the actual dataset into fewer reliable features. In recent years, processing of hyper spectral data has attracted many researchers dealing with RS image processing. Unlike the traditional multispectral data taken in the optimal range of electro-magnetic spectrum, the hyper spectral data deals with a great number of bands and many attempts are being made to reduce the dimensionality of the data and extract reliable information needed for various decision making processes [1,2,5,6]. Feature extraction for hyper spectral data is a time consuming process because it requires extensive search time until the reliable features are found. The aim of this paper is to apply different methods for feature extraction and selection of the reliable bands in classification of hyper spectral images using commercial software. For this purpose, airborne AVIRIS dataset is used. In the final classification, a traditional method of a maximum likelihood classifier (MLC) and compared. The analyses are carried out using ENVI-system initialed in a Sun-sparc workstation.
Feature Extraction Methods
For the feature extraction the following approaches have been used:
Feature extraction using principal component transformation (PCT). Here, two different approaches are used. The first method transforms the overall dataset into orthogonal axes, whereas the second method, first splits the overall dataset into groups each of which contains highly correlated bands and then transforms each dataset falling into the defined group into the principle axes.
The Study Area and Data Sources
The study area was selected in Jasper Ridge, Canada. The selected classes were settlement, gravel tin shed, deciduous forest, irrigated vegetation and soil. There was a high spectral mixture among the classes. The original AVIRIS dataset was reduced from 224 bands to 198 after water absorption bands and the bands with totally zero values were excluded.
Analysis and Discussion
The training sample selection
The training samples representing the selected classes have been selected through thorough analysis. For the selection of the training samples, two different approaches have been used:
- using polygons covering the representative pixels of the selected classes. Here, the pixels with varying radiometric values are covered by a polygon although they represent the same class;
- selecting pixels by one by one from different areas thus selecting only the representative pixels with highest purity.
Feature selection and classification
Initially, the statistics of the AVIRIS image was calculated and a correlation matrix of the bands was defined. From the correlation matrix it was seen that the bands falling into the same visible/infrared range have a high correlation (in most cases it was more than 0.9). Then, all bands of the AVIRIS image were transformed into orthogonal axes using the PCT technique. The eigenanalysis indicated that the PC1, PC2, PC3, PC4 and PC5 contain 70%, 19%, 1.6%, 2.8% and 1.2% of the total variance of the dataset.
To split the dataset, the correlation matrix was used. The bands were grouped on the basis of the highest correlation and the following groups have been defined:
Group1:bands 4-39
Group2:bands 40-100
Group3:bands 112-151
Group4:bands 170-221
Then each group was compressed by the PCT and the first PCs of the groups contained 90%, 91%, 94% and 96% of the total variance, respectively. Further, the first three PCs of the overall range and PC1 of each of the selected group were classified by MLC and spectral angle mapper (SAM) using both polygon-and pixel-based samples. As ground truth information, the regions containing the purest pixels have been selected. Confusion matrices indicated the following accuracies:
- Using polygon-based approach overall accuracies were 78.25% (MLC) and 83.80% (SAM) for the first data and 79.95% (MLC) and 83.41% (SAM) for the second data;
- Using pixel-based approach overall accuracies were 94.81% (MLC) and 84.92 % (SAM) for the first data and 97.029 % (MLC) and 85.65 % (SAM) for the second data;
In general, to define the pariwise separability of classes Jeffris-Matusita distance and divergence or some other distance measuring techniques can be used. However, in our study a simple approach of a band correlation method was used. Bearing in mind the occurrences of the available classes the bands having the lower correlation were determined. These are bands 18, 43, 121 and 84. Furthermore, the separability of the classes was compared in multi-dimensional feature space. Then, the selected bands were classified using different methods and the most accurate result has been obtained by the use of a pixel-based MLC where the overall accuracy was 93.10% while for the Sam it was 74.34%.
To define average intensity, the overall dataset was split into blue, green, red, NIR, MIRI and MIR2 ranges and the following groups have been defined:
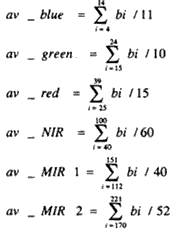
Then, they were grouped together and compressed by the PCT and the first three PCs represent 78%, 14%, and 5% of the total variance respectively. In the classification process different band combinations of PCs and average intensity have been used and classified using MLC, SAM, spectral unmixing and matched filtering techniques. The most promising result was obtained by the use of PC1 of av_red, av_NIR and av_MIR2 bands in MLC using a pixel-based approach (overall accuracy was 94.65%).
Nowadays, application of a knowledge-based approach has more and more usage in spectral classification of RS images. The knowledge in image classification can be represented in different forms depending on the type of knowledge and necessary of its usage. In our case, spectral knowledge of the classes of objects was used for selection of the features. The spectral knowledge was defined from the extensive spectral library available within the ENVI system and the general spectral characteristics of the classes of interest, as well.
The knowledge acquisition was based on the analysis of average mean spectral plot curves of the selected classes and the most appropriate bands were 17, 76, 125 or 186. Further, it was supported by knowledge gained through analysis of spectral curves loaded from the spectral library of the system. The selected bands were classified by MLC and SAM methods. The overall accuracies were 94.04% and 83.26% for both methods, respectively.
Conclusions
The overall idea of the research was to test and compare different approaches for feature extraction in hyper spectral image classification. As seen from the analysis, the traditional method of a MLC performs well in case of pure samples while SAM is better in case of scattered clusters with high spectral mixture. During the analysis, it could be seen that the increase of maximum angle radians in SAM up to 0.2-0.5 was helpful for determining of more accurate classes. Moreover, generation of the rule images, i.e., intermediate images that show the classification results before the final labeling was helpful to adjust thresholds for the classified images. Furthermore, it could be seen that to get the most reliable result, incorporation of contextual knowledge to classify pixels falling into the decision boundaries in desirable.
A further trend in this research
At present, besides the classification of RS images, image segmentation is being in more use. It would be interesting to see whether the results of image classification and segmentation coincide or not specifically on the decision boundaries between the classes. To test this, initially a RS image should be classified and overall accuracy should be as higher as possible. In the same time, the image should be segmented by the use of a combination of the image segmentation techniques. After post-classification and segmentation procedures are applied, the two results should be overlain and compared.
Acknowledgement
The authors are very grateful to JPL for providing free access to relevant data for this study.
References
- A. Cohen, D. Amarsaikhan, de Lueew, 1992, Application of GER-II Data for Geomorphological Analysis, Proceedings of ACRS, Ulaanbaatar-51, Mongolia
- A.P. Leone, 1999, Evaluation of MIVIS Hyper spectral Data for Mapping Soil Degradation in an Upland Ecosystem of Southern Italy, Geocarto International, Vol. 14, No.1, 35-43.
- ENVI,1999 User's Guide, Research Systems.
- J.A. Richards, 1993, RS Digital Image Analysis 2nd ed. Berlin, Germany: Springer-Verlag.
- Te-Ming Tu, Chin-Hsing Chen, Jiunn-Lin Wu, Chein-I Chang, 1998, A fats-two-Stage Classification Method for High-Dimensional RS Data, IEEE Trans. On Geosciences and RS, Vol.36, No.1, 182-191.
- X. Jia, J.A. Richards, 1999, Segmented Principal Components Transformation for Efficient Hyperspectral RS Image Display and Classification, IEEE Trans. On Geosciences and RS, Vol.37, No.1, 538-542.