| GISdevelopment.net ---> AARS ---> ACRS 1999 ---> Poster Session 2 |
A Study On The Design Of
Spatial Data Infrastructure (SDI) Using Activity-Based Domain Analysis
(ADA)
Tsuneki SAKAKIBARA, Ryosuke
SHIBASAKI
Center for Spatial Information Science (CSIS)
University of Tokyo
4-6-1 Komaba, Meguro-ku, Tokyo, 153-8505
Tel: 976-1-329984, Tel/Fax: 976-1-326649
Email:sakaki@skl.iis.u-tokyo.ac.jp
1. OverviewCenter for Spatial Information Science (CSIS)
University of Tokyo
4-6-1 Komaba, Meguro-ku, Tokyo, 153-8505
Tel: 976-1-329984, Tel/Fax: 976-1-326649
Email:sakaki@skl.iis.u-tokyo.ac.jp
1.1. Background
Last decade, there increase various digital information, especially spatial information in our life. A car navigation system is one of typical examples. In Japan, we can obtain some information such as running status of trains or shops’ information around where we are. It is increasing the companies and municipalities, which provide this sort of spatial information.
However, we cannot provide this sort of services easily. Nowadays, the installation costs of hardwares and softwares are relatively not so a big problem, because this is just one time investment at the installation. On the other hand, construction and revision of data require huge costs. So this investment for data is must more big problem. In addition, if the economical investment obtains adequate performance, in some case, the installation plan will be rejected. The reason is the endeavor to maintain data will be expected quite heavy.
Consequently, in the early step of use of spatial information (SI), development of a Spatial Data Infrastructure (SDI) is required to promote currency of SI and enlargement of spatial information industry.
1.2 Purpose
Therefore, in this study, we finally aim to develop a methodology to design a data architecture of SDI, effectively and efficiently. To archive this goal, we divide it into step. The first is “development of ACTIVITY-based Domain Analysis (ADA)”. We consider ADA as a methodology to analyze needs for (spatial) information. In this paper, we will discuss ADA. The second is “development of an information use model”. Using this model, we want to simulate the change of activities by the changing of provided information. The last is “development of cost-effectiveness model”. By this model, we aim to estimate the effectiveness of each data item or attribute.
2. Existing Methods – Establishment of common SI-database (SI-DB) for GIS (in Japan)
A common SI-DB has established as a GIS shared data in some division of a city office. In a city office, some division such as Asset Estimation, Road Management and supervision of housing and building has used each GIS. Some data like land lots and road has almost same or relatively close architecture for each other. Therefore, to reduce data construction and revision costs and to support efficient data currency, SI-DB has shared in some city office.
When we establish it, we decide the data architecture as the following steps.
- To list up the data which are used in each division.
- To merge those data list.
- To check out whether they will use each data items or not.
- Finally, to define the data items which will be relatively highly referred.
| Road | Building | Water Boundary | Land Lot Boundary | Railway | |
| Road | O | X | O | O | O |
| Urban Planing | O | O | O | O | O |
| Fixed Asset Taxing | 0 | 0 | O | X | O |
Surely we can extract the data architecture, but this way has some problem. By this way we cannot handle the needs of potential users such as evaluation of assets or risk in finance and insurance industry. The biggest problem is not to be able to handle daily activities. Thus if we design data architecture of SI-DB as infrastructure by this way, it must be biased toward the existing GIS users.
3. Activity-based Domain Analysis (ADA)
3.1 Activity-based domain Analysis (ADA)
ADA is a methodology to design data architecture of common SI-DB. Generally, we have to clarify the requirement on the first process of designing DB. This process is called “Concept Designing”. We use ADA on this process. Analyzing by ADA, we extract the information items and those requirements, which are used by each activity.
3.2 Terminology
In this section we define the terms that are used in ADA.
(2) Activity: An ACTIVITY is defined as an objective of each activity. For example, “To go to a customer”, “To evaluate lots to open a new brunch”. An ACTIVITY can hold a hierarchical structure. This hierarchy is composed of a sub-ACTIVITY and a super-ACTIVITY. Dividing an ACTIVITY into a set of A sub-ACTIVITY.
A Study On The Design Of Spatial Data Infrastructure (SDI) Using Activity-Based Domain Analysis (ADA)
(3) Actor: An Actor is the subject of an ACTIVITY. When we consider the ACTIVITY “to go somewhere”, we require different information between “to go from here to a station” and “from Japan to Hong Kong”. Therefore an Actor defines this difference of intention of each ACTIVITY.
(4) Application Schema (AS): Now we have to consider what an Actor see to do an ACTIVITY, and how s/he understands them. We call them an Application Schema (AS). For example, in the AS for the ACTVITY “to go from here to a station”, there are a present location, a destination, rod networks and so on. These kinds of features and feature relationships are called classes of the AS. In the example, the present location or the destination has a name, an address and so on as attributes. These are called attributes of the class.
(5) View: Each ACTIVITY has an Actor and an AS. We call a set of these three a View. Now we imaging making an urban plan. An AS of prefecture level planners and that of city are different. For example, the former deals with a prefecture as a unit. On the other hand, the later, a city. As regards road networks, the former consider national roads and prefectural roads as set, but the later, them and roads maintained by a city. Therefore, considering the difference of ASes, we should provide a data set correspond to each Actor. Especially in this sense, a View is one of the most important concepts.
(6) Dictionary: A dictionary is definition of all of information on each View. In a dictionary, it is also define that information on each aggregated ACTIVITY (refer to 3.3.3). Among Dictionaries, we define a pre-dictionary. In a Pre-Dictionary, we describe only the definition of each Actor, ACTIVITY and class of the AS. For the contents in the pre-dictionary, we make a Thesaurus.
3.3 Procedure of ADA
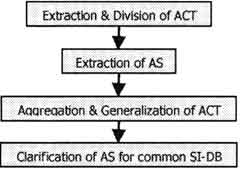
Figure 1. Procedure of ADA
ADA is composed of 4 steps: “Extraction and Division of ACTIVITIES”, “Extraction of AS”, “Aggregation and Generalization of ACTIVITES” and “Clarification of AS for common SI-DB”. Now we explain each step one by one.
(1)Extraction and Division of ACTIVITIES: On the first of ADA, we extract ACTIVITIES and divide them into sub-ACTIVITIES.
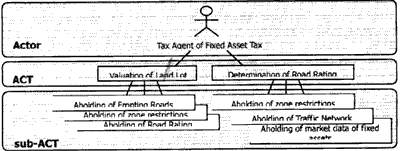
Figure 2. Extraction and Division of ACTIVITIES
At first we define Actors intended in the common SI-DB we are designing [Extraction of Actors]. When extraction Actors, it is helpful to refer the post name of present business system. Next is extraction of ACTIVITIES [Extraction of ACTIVITIES]. We consider what each Actor does and what is the purpose. This purpose is exactly and ACTIVITY. In the beginning, we should extract very rough ACTIVITIES. And we must not extract all of ACTIVITIES at once, because, when extracting ACTIVITIES for other Actors, we have some time to aware. At the last of this step, we divide each ACTIVITY into some sub-ACTIVITIES [division of ACTIVITES]. This division is done until to reach the required degree of detail of purpose. In this hierarchical structure among ACTIVITIIES, it is defined sub-ACTIVITIES are contained as a part of an ACTIVITY.
(2) Extraction of AS: In this step, we extract the AS of each ACTIVITY. In the former step, we obtained the target ACTIVITIES of SI. For the Result, i.e. all of ACTIVITY, we extract each AS. In this step, we are required only to extract the classes of an AS [making of Pre-Dictionary]. And then we represent the AS graphically [Illustration of AS]. We call this figure AS Diagram.
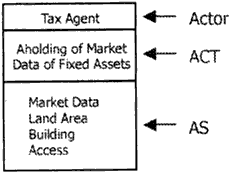
Figure 3. Actor, ACT & AS
Figure 4. AS Diagram
An AS Diagram has two functions. One is to support the matching between the AS held by actual Actors and that represented by analysts. Especially, we consider the effects will appear in the representation of topological relationships among features. Another is the role as a thesaurus. Since this AS Role has great responsibility with the next Step, we explain later. ACT
(3) Aggregation and Generalization of ACTIVITES:
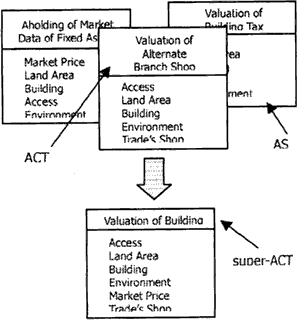
Figure 5. Aggregation and Generalization of ACTIVITES
On the third, we aggregate and Integrate ACTIVITIES. We find the candidates of ACTIVITIES, which can be aggregated into one. In this super-ACT process, just we refer the class of AS to judge their similarity. Usually doing this kind of reasoning, we will use natural language understanding methodologies. These methodologies are studied for the sentences or contexts reasoning. However, there is none Figure 5 Aggregation & Generalization of ACT of sentences or contexts for ASes.
So we do not use the methodologies. Therefore, in ADA, when we search the candidates, we use Pre-Dictionaries and AS Diagrams. By AS Diagrams, we search the first candidates roughly, reasoning by the similarity of the contents (or items) in AS Diagrams. And then we reason them referring pre-Dictionaries in detail [Aggregation of ACTIVITIES]. By the same way, we also generalize ACTIVITIES [Generalization of ACTIVITIES]. On this aggregation and generalization, we aim to the following;
To extract patterns of ACTIVITIES
To reduce Ases, which we have to clarify attributes.
To complement the missing ACTIVITIES and ASes, which should be extracted in former steps.
To recognize the rough weigh of each aggregated/generalized ACTIVITIES.
After aggregation and generalization, we integrate classes, which are belonged in the aggregated/generalized ACTIVITIES. At this time, we also integrate AS Diagram. And then we extract attributes of each integrated AS [Extraction of Attributes], and make a dictionary to define ACTIVITIES, classes and attributes of ASes [Making of Dictionary].
(4) Clarification of AS for common SI-DB: The last step of ADA is clarifying AS for a common SI-DB. On former steps, we aim to define Views, especially Ass. In this sense, each AS is related with an ACTIVITY. However it is independent for each other. Therefore, on this step, we combine and integrate those ASes into an AS for a common SI-DB. On this step, basically, we do the same aggregation and generalization on the “aggregation and generalization of ACTIVITIES”. That is aggregating and generalizing classes belonged in all of ASes referring Pre-Dictionaries and AS Diagrams. As the result, we obtain an integrated AS. This is an AS for a common SI-DB.
Figure 6. Integrated AS for common SI-DB
4. Conclusion and Future Works
In this study, we developed a structure and a procedure of ADA. At the present, by ADA we are designing a prototype of National Spatial Data Infrastructure (NSDI), which is a common SI-DB as an infrastructure. Through this examination, we could make ADA strictly. The result of ADA is a maximum data set of SI-DB. That is, we can say, a data structure of an ideal SI-DB and, it is not to set then in an actual SI-DB. So we have to evaluate them by some evaluation methods. Therefore, after developing ADA, we also develop a behavioral model to simulate the change of behavior according to provided information, and a cost model to estimate product cost of information.
Reference
- Ivan S., Richard B., Tom R., 1994. Cooperative Systems Design. The Computer Journal, 37,5, 357-366.
- Toyoaki N., Testsuo T., Takashi K., Hideaki T., 1998. Management of Engineering Knowledge, Asakura syuppan (in Japanese)
- Jones P., 1988. Practical Guide to Structured System Design Second Edition. Prenetice-hall Inc.
- Sully P., 1993. Modeling the World with Objects. Prentice Hall International Ltd.
- Yourdon E., 1994. Object-Oriented System Design An Integrated Approach. Prentice-hall Inc.
- Mitsuru I., 1997. Knowledge Representation and High Speed Reasoning. Maruzen Syuppan (in Japanese)
- Tom d., 1997. Structure Analysis and system Specification. Prenetice-Hall Inc.
- Ivar J., Maria E., Agneta J., 1994. The Object-Oriented Systems. Prenetice-Hall Inc.
- Ryoichi M., Masanobu K., 1999. An Ontology of Faults – Articulation and Organization. Journal of Japanese Society for Artificial Intelligence, 14,5.
- Mitsuru I., Satoshi K., Ryoichi M., Masanobu K., 1999 Fault Diagnosis Based on Ontological consideration of Faults – Exhaustive Fault Hypotheses Generation. Journal of Japanese Society for Artificial Intelligence, 14,5.
- Percles L., Vassilios K., 1995. System Requirements Engineering. McGraw-Hall
- Mitsuru I., Haruki U., 1997 Knowledge Representation and Use. Ohmsha
- Kaname I., 1997. Approach for System Thinking. Seibundo Printing.
- Haruo s., 1995. Fuzzy Theory. Kyoritsu Syuppan.