| GISdevelopment.net ---> AARS ---> ACRS 2000 ---> Digital Photogrammetry |
Knowledge-Based Image
Analysis for 3D Road Reconstruction
Chunsun ZHANG, Emmanuel
BALTSAVIAS, Armin GRUEN
Institute of Geodesy and Photogrammetry
ETH-Hoenggerberg, CH-8093 Zurich, Switzerland
Tel.: +41-1-6332931, Fax: +41-1-6331101
E-mail: chunsun@geod.baug.ethz.ch , manos@geod.baug.ethz.ch , agruen@geod.baug.ethz.ch
Key WordsInstitute of Geodesy and Photogrammetry
ETH-Hoenggerberg, CH-8093 Zurich, Switzerland
Tel.: +41-1-6332931, Fax: +41-1-6331101
E-mail: chunsun@geod.baug.ethz.ch , manos@geod.baug.ethz.ch , agruen@geod.baug.ethz.ch
Road reconstruction, Context, Knowledge base, Spatial reasoning
Abstract
The extraction of road networks from aerial images is one of the current challenges in digital photogrammetry and computer vision. In this paper, we present our developed system for 3D road network reconstruction from aerial images using knowledge-based image analysis. In contrast to other approaches, the developed system integrates knowledge processing of color image data and information from digital geographic databases, extracts and fuses multiple object cues, thus takes into account context information, employs existing knowledge, rules and models, and treats each road subclass accordingly. The key of the system is the use of knowledge as much as possible to increase success rate and reliability of the results, working in 2D images and 3D object space, and use of 2D and 3D interaction when needed. Another advantage of the developed system is that it can correctly and reliably handle problematic areas caused by shadows and occlusions.
1. Introduction
The extraction of roads from digital images has drawn considerable attention lately. The existing approaches cover a wide variety of strategies, using different resolution aerial or satellite images. Overviews can be found in Gruen et al. (1995, 1997a) and Foerstner and Pluemer (1997). A semi-automatic scheme requires human interaction to provide interactively some information to control the extraction. Roads are then extracted by profile matching (Airault et al., 1996, Vosselman and de Gunst, 1997), cooperative algorithms (McKeown et al., 1988), and dynamic programming or LSB-Snakes (Gruen and Li, 1997b). The automatic methods usually extract reliable hypotheses for road segments through line and edge detection and then establish connections between road segments to form road networks (Wang and Trinder, 2000). Contextual information is taken into account to guide the extraction of roads (Ruskone, 1996). Roads can be detected in multi resolution images (Baumgartner and Hinz, 2000). The existing approaches show individually that the use of road models and varying strategies for different types of scenes are promising. However, all the methods are based on relatively simplistic road models, and most of them do not make use of a prior information, thus they are very sensitive to disturbances like cars, shadows or occlusions, and do not always provide good quality results. Furthermore, most approaches work in single 2D images, thus neglecting valuable information inherent in 3D processing.
In this paper, we present a knowledge-based system for automatic extraction of 3D roads from stereo aerial images which integrates knowledge processing of colour image data and existing digital spatial databases. The system combines different input data that provides complementary, but also redundant information about road existence, therefore it can account for problematic areas caused by occlusions and shadows, and the success rate and the reliability of the extraction results are increased. The system has been developed in the project ATOMI (for details of ATOMI, see Eidenbenz et al., 2000) to improve road centerlines from digitized 1:25,000 topographic maps by fitting them to the real landscape, improving the planimetric accuracy to 1m and providing height information with 1-2m accuracy. We currently use 1:16,000 scale color imagery, with 30cm focal length, and 60% forward overlap, scanned with 14 microns at a Zeiss SCAI. The other input data include: A nationwide DTM (DHM25) with 25m grid spacing and accuracy of 2-3/5-7 m in lowland/Alps, the vectorised map data (VEC25) of 1:25,000 scale, and the raster map with its 6 different layers. The VEC25 data have a RMS error of ca. 5-7.5m and a maximum one of ca. 12.5m, including generalization effect. They are topologically correct, but due to their partly automated extraction from map, some errors exist. In addition, DSM data in the working area was generated from stereo images using MATCH-T of Inpho with 2m grid spacing.
2. Extraction Strategy & Implementation
Our approach makes full use of available information about the scene and contains a set of image analysis tools (see Fig. 1). The management of different information and the selection of image analysis tools are controlled by a knowledge-based system. The initial knowledge base is established by the information extracted from the existing geographic data and road design rules. This information is formed in object-oriented multiple object layers, i.e. roads are divided into various subclasses according to road type, land cover and terrain relief. It provides a global description of road network topology, and the local geometry for a road segment. Therefore we avoid developing a general road model, instead a specific model can be derived for each road segment. This model provides the initial 2D location of a road in the scene, as well as road attributes, such as road class, presence of road marks, and geometry (width, length, horizontal and vertical curvature, land cover and so on). A road segment is processed with an appropriate method corresponding to its model, and the knowledge base is automatically updated and refined using information gained from previous extraction of roads. The processing proceeds from the easiest subclasses to the most difficult ones. Since neither 2D nor 3D procedures alone are sufficient to solve the problem of road extraction, we make the transition from 2D image space to 3D object space as early as possible, and extract the road network with the mutual interaction between features of these spaces. More details of the general strategy can be found in Zhang and Baltsavias (2000).
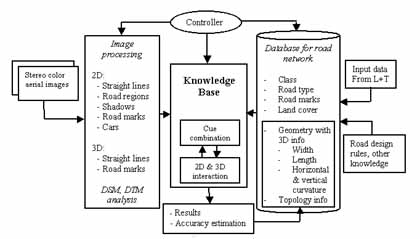
Figure. 1 Strategy of road network extraction in ATOMI. L+T: Swiss Federal Office of Topography, Bern
When a road segment is selected, the system focuses on the image regions around it and activates a set of image processing tools. Edge pixels are detected with the Canny operator, line extraction and 3D straight line generation are conducted using the methods described in Zhang and Baltsavias (2000).
An unsupervised classification method, ISODATA, is applied in image patches to separate road regions from other objects. For this purpose, 3 bands from different color spaces (derived from original color image) are used: a* from the Lab color space, one band computed with the R and G bands in RGB space as (G-R)/(G+R), and the S band from the HSI color space.
Road marks are a good indication of the existence of roads. In addition, in many cases the correct road centerlines can be derived directly from presented road marks. This is especially useful when the roadsides are occluded or not well defined, such as in cities or city centers. Road marks in high resolution images such as the one used in our work are thin lines with a certain width and distinct color (usually white or yellow), thus the road mark pixels can be roughly detected using color information. The road marks are then extracted by finding thin lines in the detected pixels. The structural matching method developed in Zhang and Baltsavias (2000) is applied to generate 3D road marks. We also detect cars on roads as an additional cue about the road existence, this is still under development.
With the information from existing geographic data and image processing, the knowledge base is established according to the general strategy. Note that one of the important characteristics of the built knowledge base is that all information in it is spatially related, and relations between 2D edges and their corresponding 3D straight lines are kept. The system then extract roads by finding 3D parallel lines that belong to a road and link them in sequence. In case of shadows, occlusions caused by trees and buildings, spatial reasoning is applied using the knowledge base. The main procedures are shown in Fig. 2. The key is the use of knowledge and image context as much as possible, working in 2D images and 3D object spaces, use of 2D and 3D interaction when needed, and reasoning the problematic area. The details of implementation can be found in Zhang (2000).
The system checks extracted lines to find 3D parallel lines. Only lines located in the buffer defined by VEC25, having a similar orientation to VEC25 segments and a certain slope are further processed. Since roads are on the ground, lines above ground are removed by checking with the DHM25. By checking with the image classification results, a relation with the road region (in, outside, at the border) is attached to each line. Two lines are considered as parallel if they have similar orientation in 3D space. The lines of a pair must overlap in direction perpendicular to the lines, and the distance between them must be within a certain range. The minimum and maximum distances depend on the road class defined in VEC25. The found 3D parallel lines are projected into the images and evaluated using multiple knowledge. The region between the projected lines must belong to the class road as determined by the image classification. Image processing tools such as those for road mark extraction are activated to extract additional cues about the road existence in the region.
The parallel lines passing the above check are considered as Possible Road Sides that are Parallel (PRSP). They compose a graph. The nodes of the graph are PRSPs, the arcs of the graph are the relations between PRSPs. Note that in occlusion areas, the arcs also represent the missing parts of a road between a pair of PRSPs. The width of two PRSPs should be similar. If there is no gap between two PRSPs with similar width, i.e. one PRSP shares points with another, and the linking angles between them in 3D space comply with VEC25, they are connected directly. In case of gap existing, the gap area is checked. This is called spatial reasoning in our development. If the gap is not too long, and 1) within the gap is a road region, e.g. a parking lot right beside road, or 2) within the gap is a shadow, or shadow mixed with road region, or 3) the gap is caused by tree occlusion (determined with image classification result and the data of DSM minus DTM), or 4) within the gap is terrain as determined by the DSM, or 5) road marks are extracted within the gap, and the connecting angles between PRSPs and gap comply with VEC25, a link is made for the two PRSPs.
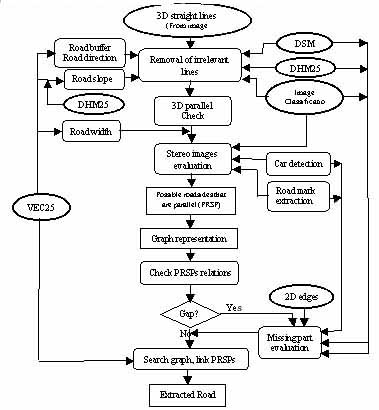
Figure.2 Procedures for road extraction.
A road hypothesis is found by searching the graph using the depth-first method. Each hypothesis is associated with a score that is the summation of the relation measurement of the PRSPs it contains. The hypothesis with the highest score is selected as road.
3. Results
The described system is implemented as a standalone software package with a graphic user interface running on SGI platforms. Fig.3 shows a road image in a rural area where the road is occluded by tree shadows. The extracted road centerline is shown in the same image in red. In Fig.4 we show the road extracted in a suburban area by the developed method. Fig. 5 is an example where the road is occluded by buildings and shadows. In Fig.6 the roadsides are not well defined, but the correct road centerline can be reliably extracted by the system through road mark extraction.
 Figure. 3 Road extraction in rural area with occlusions. |
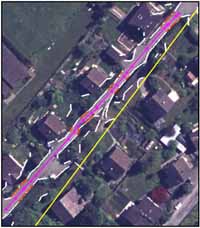 Figure. 4 Road extraction in suburban area. |
Yellow: Outdated road centerline from VEC25
White: Extracted straight lines in road buffer
Orange: Found 3D parallel lines
Red: Extracted road centerline
 Figure. 5 Buildings occlude the road. |
 Figure. 6 Road extraction through road mark extraction |
We presented a knowledge-based image analysis system for road extraction from stereo aerial images. The system has several advantages over other approaches. It uses existing knowledge, image context, rules and models to restrict search space, treats each road subclass differently, checks the plausibility of multiple possible hypotheses, and derives reliable criteria, therefore provides reliable results. The system contains a set of image processing tools to extract various cues about road existence, and fuse multiple cues and existing information sources. This fusion provides information not only complementary, but also redundant to account for errors and incomplete results. Working on stereo images, the system makes an early transition from 2D image space to 3D object space. The road hypothesis is generated directly in 3D object space. This not only enables us to apply more geometric criteria to create hypotheses, but also largely reduces search spaces, and speeds up the process. The hypotheses are evaluated in 2D images using accumulated knowledge information. Whenever 3D features are incomplete or entirely missing, 2D information from stereo images is used to infer the missing features. By incorporating multiple knowledge, the problematic areas caused by shadows, occlusions etc. can be handled. Our future work will concentrate on road extraction in city and city center. Another important issue is the measurement of reliability of the extraction results. A method will be developed to quantify reliability using accumulated knowledge information. In order to evaluate the extraction results, a metric and method for evaluation will also be developed in future.
Acknowledgements
We acknowledge the financial support of this work and of project ATOMI by the Swiss Federal Office of Topography, Bern.
References
- Airault, S., Jamet, O., Leymarie, F. 1996: From Manual to Automatic Stereoplotting: Evaluation of Different Road Network Capture Processes. IAPRS, Vol.31, Part B3, pp.14-18.
- Baumgartner, A., Hinz, H. 2000: Multi-Scale Road Extraction Using Local and Global Grouping Criteria. IAPRS Vol.33, Part B3/1, pp.58-65.
- Eidenbenz Ch., Kaeser Ch., Baltsavias E., 2000. ATOMI - Automated Reconstruction of Topographic Objects from Aerial Images using Vectorized Map Information. IAPRS, Vol.33, Part 3/1, pp.462-471.
- Foerstner, W., Pluemer L. (Eds.), 1997. Semantic Modeling for the Acquisition of Topographic Information from Images and Maps. Birkhaeuser Verlag, Basel.
- Gruen A., Kuebler O., Agouris P. (Eds.), 1995. Automatic Extraction of Man-Made Objects from Aerial and Space Images. Birkhaeuser Verlag, Basel.
- Gruen A., Baltsavias E.P., Henricsson O. (Eds.), 1997a. Automatic Extraction of Man-Made Objects from Aerial and Space Images (II). Birkhaeuser Verlag, Basel.
- Gruen A., Li H., 1997b. Semi-Automatic Linear Feature Extraction by Dynamic Programming and LSB-Snakes. Photogrammetric Engineering and Remote Sensing, 63(8), pp.985-995.
- McKeown, D.M., Denlinger, J.L., 1988: Cooperative Methods for Road Tracking in Aerial Imagery. Proc. of IEEE Computer Vision and Pattern Recognition, Michigan, pp.662-672.
- Ruskone, R., 1996: Road Network Automatic Extraction by Local Context Interpretation: Application To the Production of Cartographic Data. Ph.D. Thesis. Marne-La-Vallee University, France.
- Vosselman, G., de Gunst, M., 1997: Updating Road Maps by Contextual Reasoning. Automatic Extraction of Man-Made Objects from Aerial and Space Images (II), A. Gruen, E.P. Baltsavias and O. Henricsson (Editors), Birkhäuser Verlag, Basel, pp. 267-276.
- Wang Y., Trinder J, 2000: Road Network Extraction by Hierarchical Grouping. IAPRS, Vol.33, Part B3/2, pp.943-949.
- Zhang C. and E.P.Baltsavias, 2000: Knowledge-based Image Analysis for 3D Edge Extraction and Road Reconstruction, IAPRS, Vol.33, PartB3/2, pp.1008-1015.
- Zhang C., 2000: ATOMI Intermediate Report on Road Extraction. Institute of Geodesy and Photogrammetry, ETH Zurich.